python_6 with 컴퓨팅사고(김완섭 ch14~)
1.len(): 문자열의 길이만 알려줌
import sys sys.getsizeof() : 메모리 바이트크기를 알려줌
lower(): 모두 소문자
upper(): 모둔 대문자
capitalize() : 첫문자만 대문자 나머지는 소문자

#capitalize()는 띄어쓰기한 문자는 대문자로 바꿔주지 않는다. P가 아니라 p임
2.점검함수들
ㅇ십진수인가?
"2020".isdecimal()

#그리 중요한부분은 아닌듯.
isalpha(): 문자로만 구성(영어or한국어)
isnum():숫자로만 구성
isalnum(): 숫자랑 문자로만 구성
islower(): 소문자로만구성
isidenifier(): 식별자(변수이룸)으로 사용가능?
2_1)식별함수 만들기. 실수/정수 식별함수
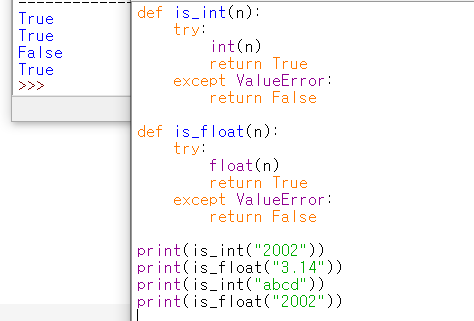
#float()는 정수도 True 리턴한다.
#try랑 except ValuError는 처음본다.
3.불필요한 공백처리 - sns에서 덧글 데이터분석시 쓰인다.
strip(): 문자열 양끝의 공란을 제거
lstrip(): 문자열 왼쪽의 공백을 제거
rstrip():

#strip()이나 lstrip()이나 별반차이가 없다.
4.replace("a","b") : 2 파라미터를 입력. 첫번째 파라미터를 찾아서 두번째 파라미터 변경

#그냥 t.replace() 바로 쓰지말고 t=t.replace()처럼 자신에게 대입하는 과정 반드시 하기
#문자열에 포함된 모든 공백을 제거해보라고 해서 replace(" ", "")로 대입
#정보검색분야에서 공백을 제거하는것이 왜 필요한지 생각해보라고 한다.
>>앞서 len()이나 sys.getsizeof()를 다뤘는데 공백도 메모리를 차지하기 때문에 불필요한 용량을 줄이기 위함인듯
5.문자열 인덱스 a[0]~a[n-1]
6.문자열 슬라이싱: 특정 웹페이지 html에 포함된 특정정보를 가져올때
str[N:M] : M-1인덱스까지 출력

0 1 2 3 4 5 6 7 8 9 10 11
H e l l o p y t h o n
-12 -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1
#역인덱스 슬라이싱: 데이터사이언스에서 텍스트처리할때 필수적으로 사용된다고 함.
-계산시에는 총문자수-인덱스숫자: ex)총12자리-3인덱스(4번째글자): 9 -> 음수붙이기
ex) strawberry : 10글자고, w(5번째, 인덱스로는 [4])의 역인덱스를 알고싶으면 10-4=>-6이다
따라서 a=strawberry, a[-6:-1]하면 wberr 선택된다.

#a[-6:0]으로 하면 공백출력된다.
6_1)예제: 주민등록번호 앞6자리르 받아서 출생년도, 생일, 나이를 출력해주는 프로그램을 작성하라
(단, 2000년도 이전 출생자로 한정)

#m이랑 d에 int()없이 a[:]로만 줄때는 01월 01일로 출력되는데 int() 추가하면 1월 1일로 출력된다.
6_2)예제: 주민등록번호 앞7자리 받아서 성별까지 출력하는 프로그램만들기
7번째 번호
1: 1900~1999년 출생 남성
2: 1900~1999 출생 여성
3: 2000~2099 출생 남성
4: 2000~2099 출생 여성
인덱스
0 1 2 3 4 5 6 7
0 1 0 1 1 2 - 3
-8 -7 -6 -5 -4 -3 -2 -1

7.특정단어 검색
in키워드 : 문자열 안에 검색하고자 하는 문자열이 존재하는가 판단. True, False


#???"안녕"혹은 "반가워" 사용시 둘다 같은 문자열을 출력하고 싶은데 안된다. 물어봐야지......
find(): 문자열에 특정문자가 있는가. 문자열이 존재하는 위치(인덱스)값을 찾아줌
0~n-1까지 값이 나올것이며 불일치하는 문자열 입력시 -1을 리턴
count(): 특정단어가 몇번 포함되는지 세는 함수. 미포함단어는 0을 출력

8.문자열 쪼개기, 붙이기
split(): 분리문자를 기준으로 여러개의 문자열로 분할 후 리스트를 만든다
cf) sep=구분자, end=끝문자
join(): 하이픈(-)첨가하거나

8_1) input()과 split() 응용
a,b=input("입력").split()
두개의 정수 x,y를 입력받아 사칙연산을 수행하는 프로그램.

#input으로 입력받은 숫자는 문자로 인식되므로 x=int(a)로 변환해줄것
str="abc"
for x in str:
print(x)
>>>
a
b
c
9.리스트
리스트는 동일한 형태의 값을 가질필요는 없다. ['a', 11, 1.4]
a=list([1,20,3])
[1, 4, 7, 10, 13, 16, 19]
len() 사용가능 : 문자열/ 리스트길이 확인할때
9_1 append() 리스트 맨뒤에 값추가 (한개의 값)
insert( , ) 리스트 특정위치에 값추가
ex) a=[1,2,3,4,5]
for item in a:
print(item) #item이 5글자이기 때문
>>>1
>>>2
>>>3
>>>4
>>>5

9_2 extend(): 여러값을 리스트에 한꺼번에 추가 (+연산자도 가능)
a=[1,2,3]
b=[4,5,6]
c=a+b #c=a.extend(b)
print(c)
>>>[1,2,3,4,5,6]
ylist=[]
for x in xlist:
y=5*x+10
ylist.append(y)
==
ylist=[5*x+10 for x in xlist]
#for문으로 여러줄 썼던거 한줄로 가능

9_3 응용문제_1: 키와 표준몸무게를 리스트에 저장하기
키 150~180cm까지 3cm단위로 표준몸무게를 표시해주는 프로그램. 순번과, 키, 몸무게를 출력하라.

#헷갈리니까 다시짜보기 변수 h랑 len(hlist) 주의
응용문제_2: 사인함수 그리기
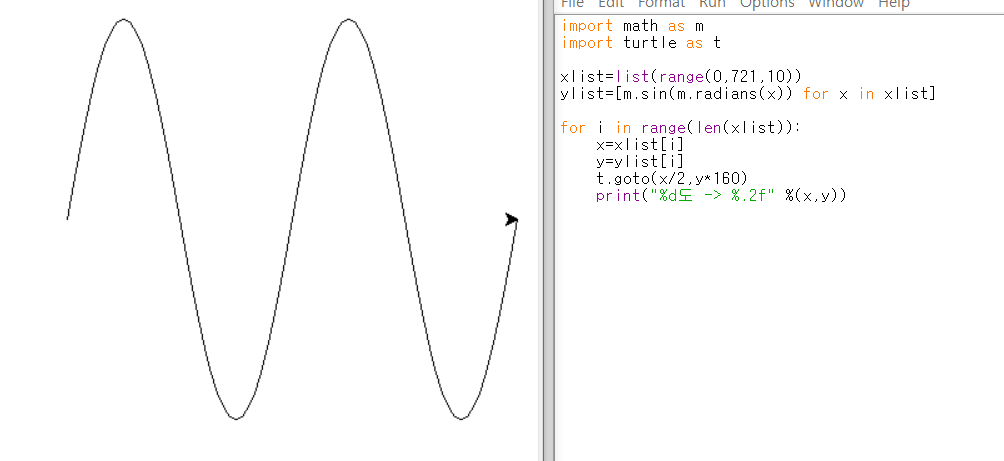
#그래프가 잘 안보여서 x/2, y*160했다.
9_4) 리스트활용함수들
append()
insert()
extend()
count() 리스트에 포함된 특정값의 항목의 개수를 리턴
remove() 리스트에서 입력값과 같은 항목들을 하나만 지운다.
index()
sort() 오름차순으로 정렬한다.
reverse()
pop() 맨뒤에 있는 항목을 리턴, 리스트에서는 삭제
a=[10,20,10,10,20]
a.count(10)
3
a.remove(10)
print(a)
[20,10,10,20]
a.sort()
print(a)
[10,10,20,20]
a.pop() #끝에있는 값 삭제
print(a)
[10,10,20]
10.튜플. (리스트와의 차이점: 자료가 변경될 수 있는가?-append() insert() remove() del tuple[0] 안됨. )
but 리스트보다 빠른속도
튜플은 괄호() 생략가능
예제) 학생의 1차, 2차,3차, 4차 시험성적을 입력받아 리스트에 저장. 4번시험의 평균점수를 화면에 출력.
각 시험의 가중치를 10% 20% 30% 40%로 지정하여 평균점수를 계산하라. 뒤에본 시험일수록 가중치가 높다.

11.딕셔너리 {key: value} : 리스트는 하나의 항목의 연결된 자료형/ 딕셔너리는 키와 값의 정보가 한쌍
keys(): 키 값들을 리스트로 출력
values(): 값들을 리스트로 출력
items() 한쌍으로 리턴
dict['키']: 밸류를 출력
get(): 밸류출력
in 키워드: '키값' in 딕셔너리
추가: dict['']='밸류'
삭제: del dict['']
전체삭제: dict.clear()
query: 데이터베이스에 정보를 요청하는 것

#리스트에서는 len(a), 딕셔너리에서는 a.keys()

item()함수-튜플형태 쓴거랑 for문으로 작성한것 비교.
11_1. 프로그래밍 언어 개발연도 안내챗봇

*메모장의 데이터 이용하기
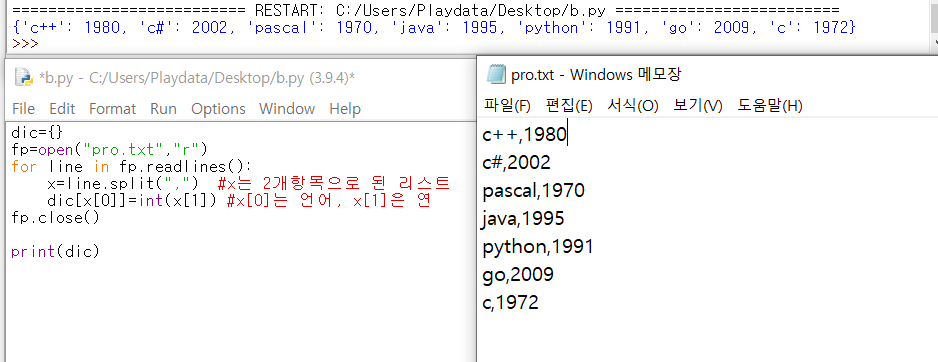

11_2: 동물명 영어사전 프로그램
텍스트파일에 동물(kr) (en) 15가지 생성해서, 파이썬으로 받기.
query에 해당되는 단어 받으면 대응하는 값 출력해주기

# UnicodeDecodeError: 'cp949' codec can't decode byte 0x9c in position 2: illegal multibyte sequence
자꾸 이런 에러메세지가 뜨길래 구글링해서 encoding='UTF-9'도 추가해줌.
#replace도 뭔지 잘 모르겠는데 일단 따라서 적어봄
#딕셔너리로 굉장히 기본적인 데이터 처리할 수 있을듯. 나라-수도 연결. 상품명-가격 연결 etc